DW SubDAG
S3 Data Lake로 적재 한 소스 데이터를 DW 분석의 전형적인 star schema 형태로 변환 하기 위한 DAG 오브젝트를 구성합니다. AWS에는 데이터를 처리하는 다양한 서비스가 있으며, 본 실습에서는 Athena를 사용하여 작은 규모의 dimension table을 처리하는 작업을 수행하고 EMR Spark을 사용하여 보다 큰 규모의 fact table을 처리하는 것을 가정합니다.
DW의 작업 또한 반복적인 패턴의 작업이 있기 때문에 Main DAG를 단조롭게 하기 위해 sub DAG를 구성합니다. 따라서, Athena 쿼리를 수행하여 dimension table을 처리하는 작업과 EMR Spark 환경을 구성하여 fact table을 처리하는 작업을 하나의 DAG 오브젝트로 구성하겠습니다.
- 다음 스크립트를 Cloud9 workspace로 copy/paste하여 dags/chinookSubDAG 폴더 안에
chinook_dwh_subDAG.py를 생성 하십시오.
from airflow.models import DAG
from airflow.models import Variable
from airflow.providers.amazon.aws.operators.s3_delete_objects import S3DeleteObjectsOperator
from airflow.providers.amazon.aws.operators.athena import AWSAthenaOperator
from airflow.providers.amazon.aws.operators.emr_add_steps import EmrAddStepsOperator
from airflow.providers.amazon.aws.operators.emr_create_job_flow import EmrCreateJobFlowOperator
from airflow.providers.amazon.aws.operators.emr_terminate_job_flow import EmrTerminateJobFlowOperator
from airflow.providers.amazon.aws.sensors.emr_step import EmrStepSensor
# Airflow connections
AWS_CONN='aws_default'
# UI variables
CURRENT_YEAR=Variable.get('CURRENT_YEAR')
CURRENT_MONTH=Variable.get('CURRENT_MONTH')
DATALAKE_BUCKET=Variable.get('DATALAKE_BUCKET')
PROJECT_BUCKET=Variable.get('PROJECT_BUCKET')
ODS_DB=Variable.get('ODS_DB')
DWH_DB=Variable.get('DWH_DB')
# DW SQLs
DWH_DROP_DIM_TRACK_TABLE="DROP TABLE IF EXISTS dim_track"
DWH_CREATE_DIM_TRACK_TABLE=\
f"""
CREATE TABLE dim_track
WITH (
external_location = 's3://{DATALAKE_BUCKET}/dwh/dim_track/',
format = 'Parquet',
parquet_compression = 'SNAPPY'
)
AS
SELECT
tr.trackid as "track_id",
tr.name, tr.composer,
tr.milliseconds,
tr.bytes, tr.unitprice,
ar.name as "artist",
al.title as "album",
ge.name as "genre",
me.name as "media_type"
FROM {ODS_DB}.artist ar
INNER JOIN {ODS_DB}.album al ON ar.artistid = al.artistid
INNER JOIN {ODS_DB}.track tr ON al.albumid = tr.albumid
INNER JOIN {ODS_DB}.genre ge ON tr.genreid = ge.genreid
INNER JOIN {ODS_DB}.mediatype me ON tr.mediatypeid = me.mediatypeid
"""
DWH_DROP_DIM_CUSTOMER_TABLE="DROP TABLE IF EXISTS dim_customer"
DWH_CREATE_DIM_CUSTOMER_TABLE=\
f"""
CREATE TABLE dim_customer
WITH (
external_location = 's3://{DATALAKE_BUCKET}/dwh/dim_customer/',
format = 'Parquet',
parquet_compression = 'SNAPPY'
)
AS
SELECT customerid as "customer_id", firstname as "first_name", lastname as "last_name",
company, address, city, state, country, postalcode as "postal_code", phone,
fax, email, supportrepid as "support_rep_id"
FROM {ODS_DB}.customer
"""
DWH_DROP_DIM_INVOICE_TABLE="DROP TABLE IF EXISTS dim_invoice"
DWH_CREATE_DIM_INVOICE_TABLE=\
f"""
CREATE TABLE dim_invoice
WITH (
external_location = 's3://{DATALAKE_BUCKET}/dwh/dim_invoice/',
format = 'Parquet',
parquet_compression = 'SNAPPY'
)
AS
SELECT invoiceid as "invoice_id", billingaddress as "billing_address", billingcity as "billing_city",
billingstate as "billing_state", billingcountry as "billing_country", billingpostalcode as "billing_postal_code"
FROM {ODS_DB}.invoice
"""
table_list = [ 'dim_track', 'dim_customer', 'dim_invoice' ]
drop_sql_dict = {
'dim_track': DWH_DROP_DIM_TRACK_TABLE, \
'dim_customer': DWH_DROP_DIM_CUSTOMER_TABLE, \
'dim_invoice': DWH_DROP_DIM_INVOICE_TABLE
}
create_sql_dict = {
'dim_track': DWH_CREATE_DIM_TRACK_TABLE, \
'dim_customer': DWH_CREATE_DIM_CUSTOMER_TABLE, \
'dim_invoice': DWH_CREATE_DIM_INVOICE_TABLE
}
# Helper Function: Returns DAG that create DW dimension tables
def create_dwh_dim_table_subdag(parent_dag_name, child_dag_name, default_args):
with DAG(
dag_id='%s.%s' % (parent_dag_name, child_dag_name),
default_args=default_args
) as dag:
for table_name in table_list:
if table_name == 'fact_invoice':
s3_prefix = f'dwh/{table_name}/year={CURRENT_YEAR}/month={CURRENT_MONTH}/'
else:
s3_prefix = f'dwh/{table_name}/'
t1 = S3DeleteObjectsOperator(
task_id=f'clear_{table_name}_data',
bucket=DATALAKE_BUCKET,
prefix=s3_prefix,
aws_conn_id=AWS_CONN
)
t2 = AWSAthenaOperator(
task_id=f'drop_{table_name}_table',
query=drop_sql_dict[table_name],
database=DWH_DB,
output_location=f"s3://{PROJECT_BUCKET}/athena_query_results/",
aws_conn_id=AWS_CONN,
workgroup="primary"
)
t3 = AWSAthenaOperator(
task_id=f'create_{table_name}_table',
query=create_sql_dict[table_name],
database=DWH_DB,
output_location=f"s3://{PROJECT_BUCKET}/athena_query_results/",
aws_conn_id=AWS_CONN,
workgroup="primary"
)
t1 >> t2 >> t3
return dag
# EMR Cluster configuration
JOB_FLOW_OVERRIDES = {
'Name': 'demo-spark-cluster',
'ReleaseLabel': 'emr-6.2.0',
'Applications': [
{
'Name': 'Spark'
}
],
"Configurations": [
{
"Classification": "spark-hive-site",
"Properties": {
"hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
}
],
'Instances': {
'InstanceGroups': [
{
'Name': 'Master nodes',
'Market': 'ON_DEMAND',
'InstanceRole': 'MASTER',
'InstanceType': 'm5.xlarge',
'InstanceCount': 1,
},
{
'Name': 'Slave nodes',
'Market': 'ON_DEMAND',
'InstanceRole': 'CORE',
'InstanceType': 'm5.xlarge',
'InstanceCount': 1,
}
],
'KeepJobFlowAliveWhenNoSteps': True,
'TerminationProtected': False
},
'VisibleToAllUsers': True,
'JobFlowRole': 'EMR_EC2_DefaultRole-mwaa-workshop',
'ServiceRole': 'EMR_DefaultRole-mwaa-workshop',
'Tags': [
{
'Key': 'Project',
'Value': 'Airflow Demo'
}
]
}
# EMR Spark Step configuration
EMR_STEPS = [
{
'Name': 'Invoice Fact Table Processing Step',
'ActionOnFailure': 'CONTINUE',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': ['spark-submit', '--deploy-mode', 'cluster', \
f's3://{PROJECT_BUCKET}/scripts/spark/create_dwh_fact_invoice_table.py', \
DATALAKE_BUCKET, ODS_DB, DWH_DB, CURRENT_YEAR, CURRENT_MONTH]
},
}
]
# Helper Function: Returns DAG that create DW fact table
def create_dwh_fact_table_subdag(parent_dag_name, child_dag_name, default_args):
with DAG(
dag_id='%s.%s' % (parent_dag_name, child_dag_name),
default_args=default_args
) as dag:
# Create EMR cluster
t1 = EmrCreateJobFlowOperator(
task_id='create_emr_cluster',
job_flow_overrides=JOB_FLOW_OVERRIDES,
aws_conn_id=AWS_CONN,
)
# Add EMR Spark step
t2 = EmrAddStepsOperator(
task_id='add_spark_step_for_fact_table',
job_flow_id="{{ task_instance.xcom_pull(task_ids='create_emr_cluster', key='return_value') }}",
aws_conn_id=AWS_CONN,
steps=EMR_STEPS
)
# Wait step completion
t3 = EmrStepSensor(
task_id='wait_for_step_complete',
job_flow_id="{{ task_instance.xcom_pull('create_emr_cluster', key='return_value') }}",
step_id="{{ task_instance.xcom_pull(task_ids='add_spark_step_for_fact_table', key='return_value')[0] }}",
aws_conn_id=AWS_CONN
)
# Terminate EMR cluster
t4 = EmrTerminateJobFlowOperator(
task_id='terminate_emr_cluster',
job_flow_id="{{ task_instance.xcom_pull(task_ids='create_emr_cluster', key='return_value') }}",
aws_conn_id=AWS_CONN
)
t1 >> t2 >> t3 >> t4
return dag
-
스크립트 구성을 살펴 보겠습니다. 먼저 DAG를 구성하기 위해 필요한 Airflow library를 import 합니다. 특히 S3, Athena 및 EMR 작업이 필요하므로 AWS Operator library가 사용 됩니다. 그리고 Airflow 작업이 AWS 서비스와 연결 하기 위해 기본 구성 되 있는 aws_default 연결을 사용하며, 또한 Airflow UI에 정의 된 Variables (변수)를 Global 변수로 선언하여 사용합니다.

-
DW의 dimension table을 생성하는 작업은 Athena 쿼리를 통해 수행합니다. 따라서 Glue Catalog에 정의 된 ODS table을 소스로 사용하는 Drop table, Create table 쿼리 세트가 각 테이블 별로 정의 되 있습니다.

-
create_dwh_dim_table 함수는 S3 Data Lake 에 형성 된 ODS 데이터를 기반으로 DW의 dimension table을 생성하기 위한 DAG 오브젝트를 구성합니다. 첫번째 S3DeleteObjectsOperator의 작업은 dimension table의 데이터를 생성하는 작업이 여러 번 수행 되도 중복 데이터가 S3 Data Lake bucket에 생성되는 것을 방지 하기 위해 기존에 생성 된 S3 오브젝트를 삭제하는 작업을 정의합니다. 그리고 다음 두 개의 AwsAthenaOperator의 작업은 앞서 정의 한 각 테이블의 Drop table 및 Create table 쿼리 문을 사용하여 최신 dimension table을 생성하기 위한 작업을 정의합니다.
각 테이블 별로 clear_<table_name>_data_in_s3, drop_<table_name>_table, create_<table_name>_table 이름의 작업이 Airflow DAG에 생성 됩니다.

-
DW의 fact table을 생성하는 작업은 EMR Spark job을 통해 수행 합니다. 따라서 EMR cluster를 프로비져닝 하기 위한 Configuration 정보와 cluster가 생성 된 이후 Spark script를 EMR step 프로세스로 실행하기 위한 정보를 정의 합니다.

-
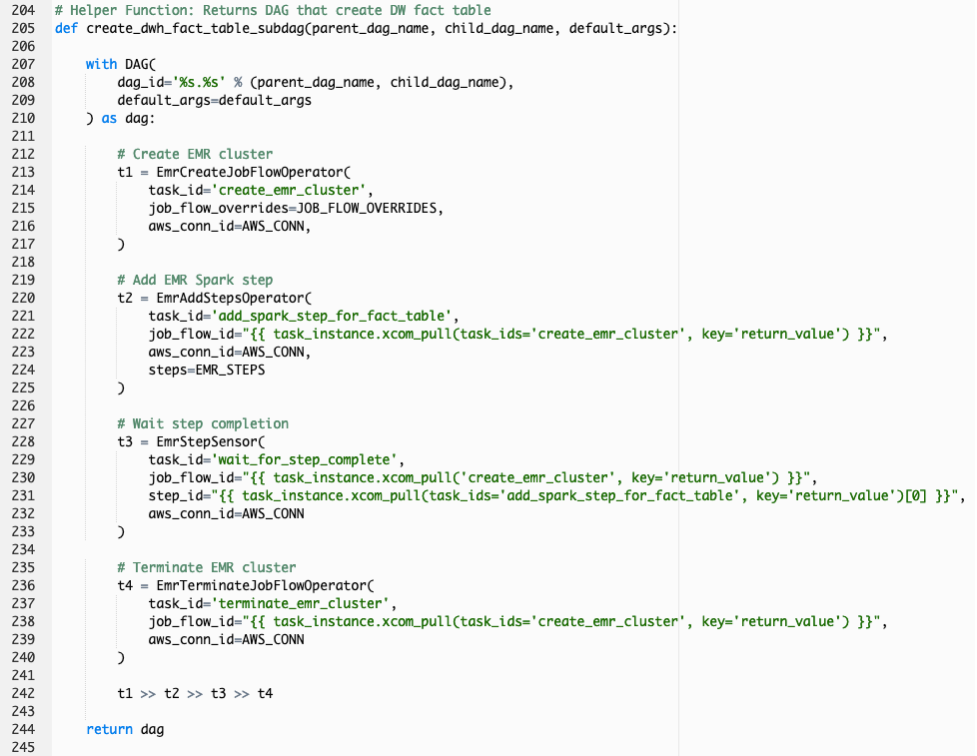
create_dwh_fact_table 함수는 S3 Data Lake 에 형성 된 ODS 데이터를 기반으로 DW의 fact table을 생성하기 위한 DAG 오브젝트를 구성합니다. 첫번째 EmrCreateJobFlowOperator의 작업은 EMR cluster configuration 정보를 기반으로 EMR cluster를 프로비져닝하기 위한 작업을 정의하고, 두번째 EmrAddStepsOperator의 작업은 Spark job을 EMR step 프로세스로 추가하기 위한 작업을 정의합니다. 그리고 EmrStepSensor의 작업은 EMR step의 Spark job이 완료 될 때까지 대기하기 위한 작업을 정의합니다. 마지막으로 EmrTerminateJobFlowOperator의 작업은 EMR cluster를 종료하기 위한 작업을 정의합니다. 이러한 작업 순서대로 DW의 fact table을 구축하는 작업이 전개 됩니다.
-
Airflow UI의 Admin->Variables 화면으로 가서 DAG 스크립트에서 사용하는 Airflow 변수를 다음 테이블의 정보를 참조하여 생성 하십시오.
| Key | Val |
|---|---|
DWH_DB |
chinook_dwh |
