DAG Run
-
DAG를 실행하려면 Airflow cluster가 S3, Glue, Athena 및 EMR 서비스에 접근 할 수 있는 권한이 필요합니다. Amazon MWAA 콘솔에서 MWAA 환경을 클릭하면 다음과 같이 cluster에 연결 된 IAM execution role을 확인 할 수 있습니다. Execution role 링크를 클릭하여 IAM 콘솔로 이동 하십시오.
-
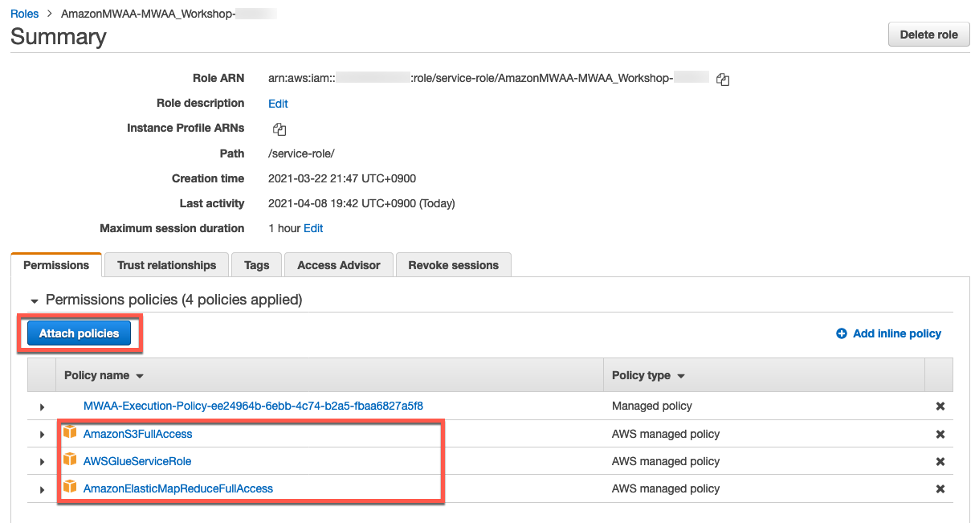
다음과 같은 3개의 Managed 정책을 추가 하십시오.
프로덕션 환경에서 IAM 정책을 생성 할 때 최소 권한을 부여하거나 작업을 수행하는 데 필요한 권한 만 부여하는 표준 보안 권고를 따르십시오.
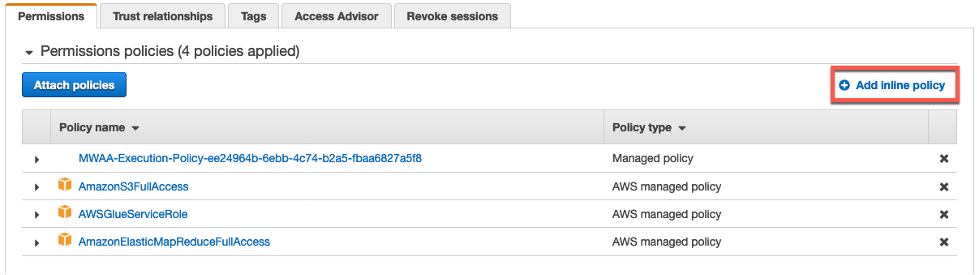
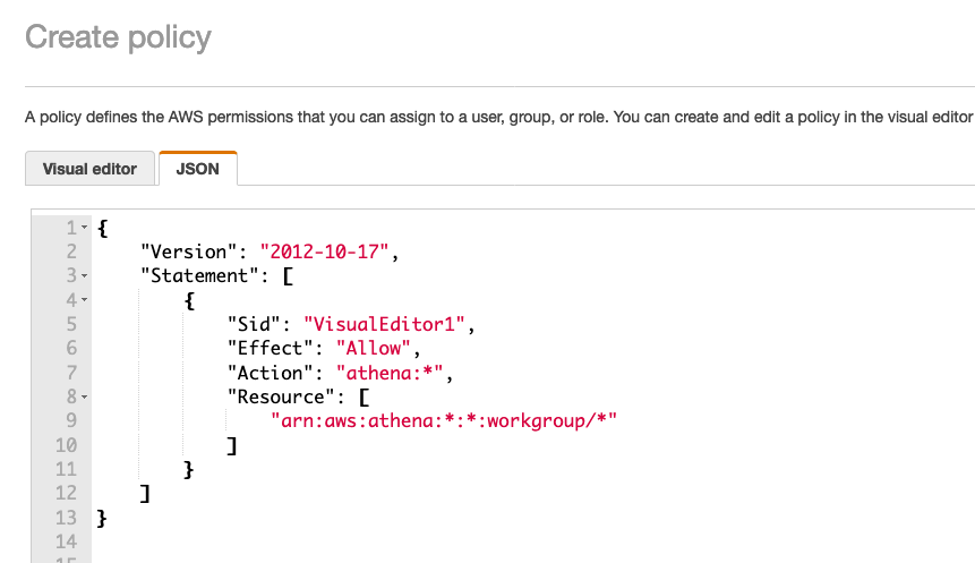
- Athena 권한을 위한 Inline 정책을 추가 하겠습니다. 오른쪽에 Add inline policy을 클릭하고 다음 JSON 정책 문서를 copy/paste 하십시오.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "athena:*",
"Resource": [
"arn:aws:athena:*:*:workgroup/*"
]
}
]
}
-
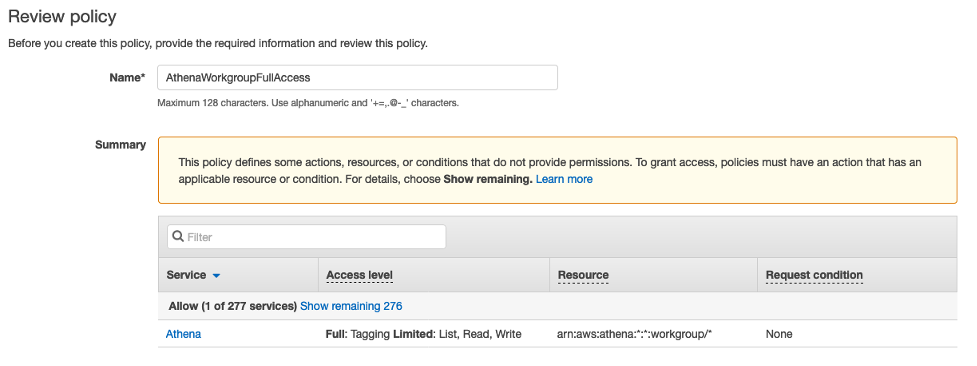
Inline 정책 이름을 입력하고 정책을 생성 하십시오.
-
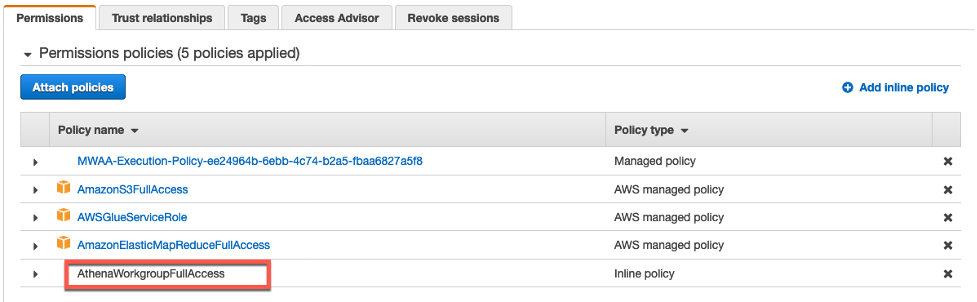
최종적으로 Inline 정책 또한 IAM role에 추가 된 것을 확인 하십시오. 이제 MWAA 환경은 AWS 서비스를 액세스 할 수 있는 권한을 부여 받았습니다.
-
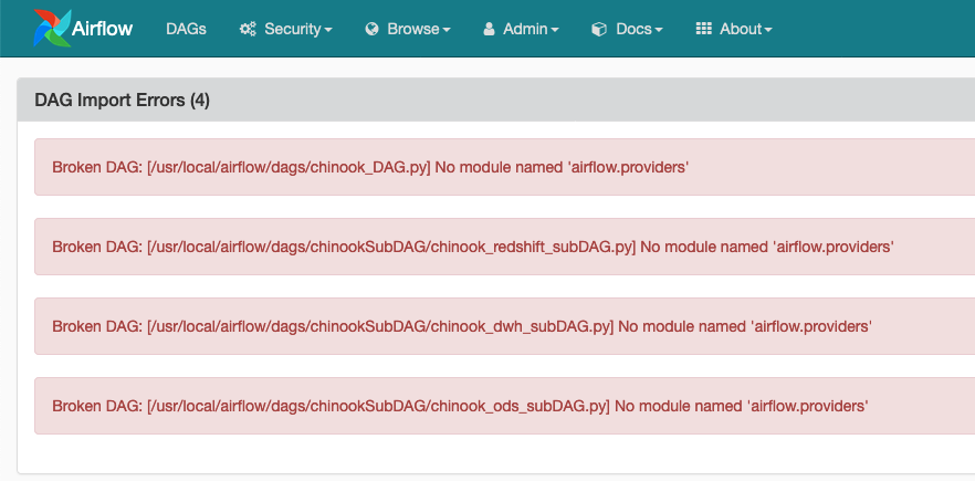
Airflow UI를 reload 하십시오. 그러면 다음과 같이 airflow.providers 모듈의 관한 에러 메시지가 발생하여 DAG가 성공적으로 import 되지 못합니다. 이 문제를 해결하려면 Airflow 환경에 필요한 Python package를 추가적으로 설치해야 합니다.
Amazon MWAA는 Python package를 설치하기 위해 S3 bucket에 위치한 requirements.txt 파일을 사용합니다.
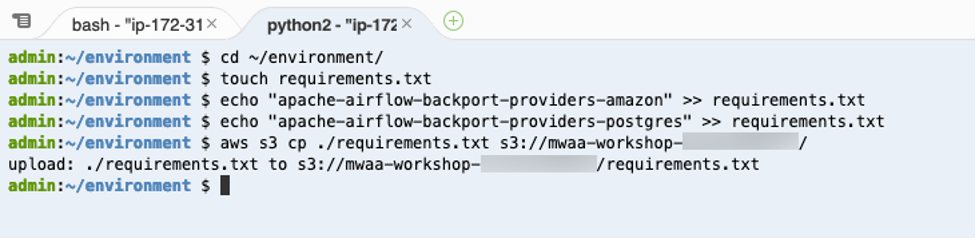
- 다음 명령어를 Cloud9 workspace의 terminal에서 실행하여 requirements.txt 파일을 생성하고 파일을 Airflow S3 bucket으로 업로드 하십시오.
CLI를 실행하기 전에 <your_aws_account_id> 문구는 현재 사용하고 있는 12자리 AWS Account ID로 변경해야 합니다.
cd ~/environment
touch requirements.txt
echo "apache-airflow-backport-providers-amazon" >> requirements.txt
echo "apache-airflow-backport-providers-postgres" >> requirements.txt
aws s3 cp ./requirements.txt s3://mwaa-workshop-<your_aws_account_id>/
-
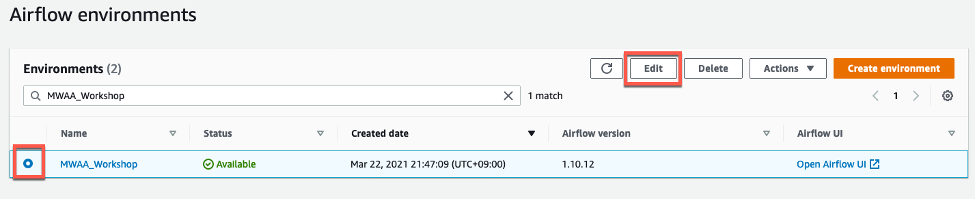
MWAA 환경을 수정하여 requirements.txt 파일의 S3 위치를 입력해야 합니다. 다음과 같이 MWAA 환경을 선택하고 Edit 버튼을 클릭 하십시오.
-
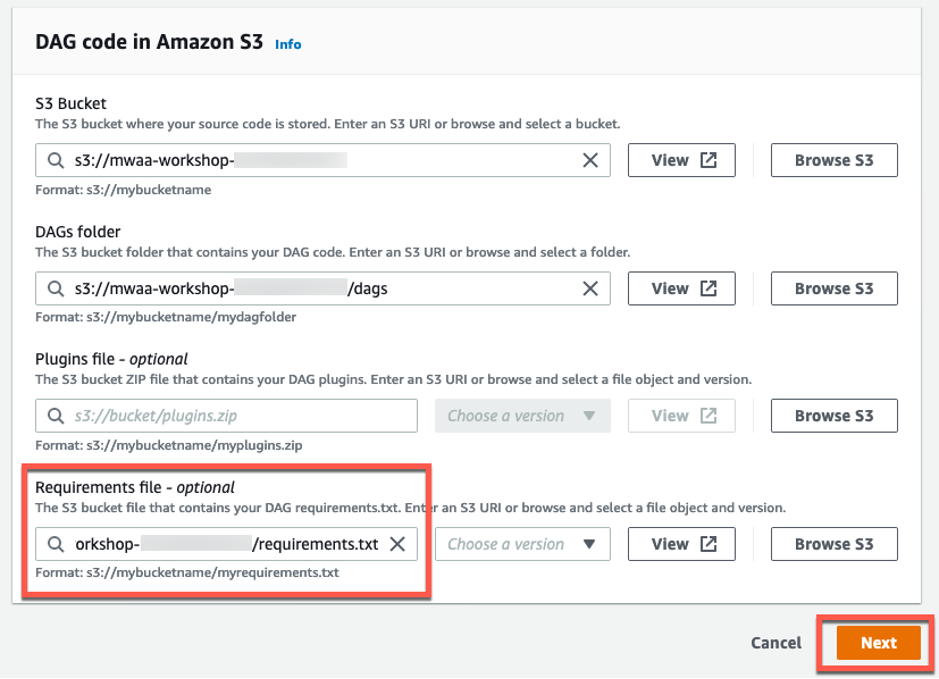
Requirements.txt 파일의 S3 위치를 입력하고 Next 버튼을 클릭하십시오. MWAA 환경의 다른 모든 설정은 그대로 유지하고 마지막 Review and save 페이지로 넘어가 Save 버튼을 클릭 하십시오.
-
MWAA 환경의 상태는 업데이트 중으로 표시 됩니다. 상단 메뉴에 Refresh 버튼을 클릭하여 상태를 확인 할 수 있습니다. Available 상태로 변경 되기까지 대략 5분 정도의 시간이 소요됩니다.


-
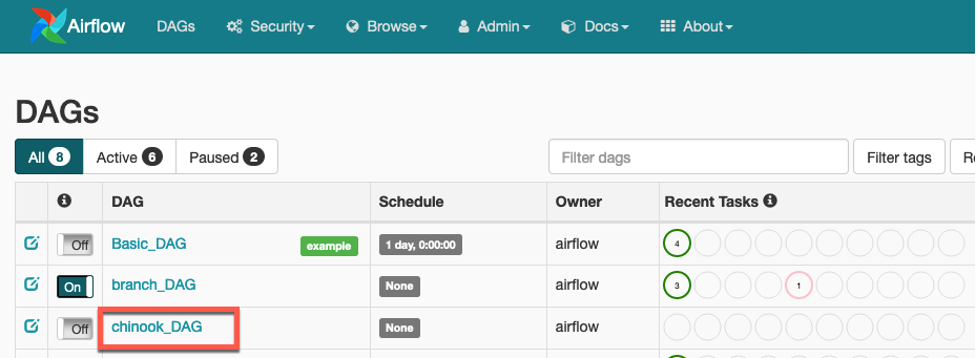
Airflow UI를 reload 하십시오. 그러면 Airflow UI에 chinook_DAG가 DAG 목록에 나타납니다.
-
Graph View로 가서 Main DAG의 Workflow가 다음 화면과 같은 모습인지 확인하십시오.
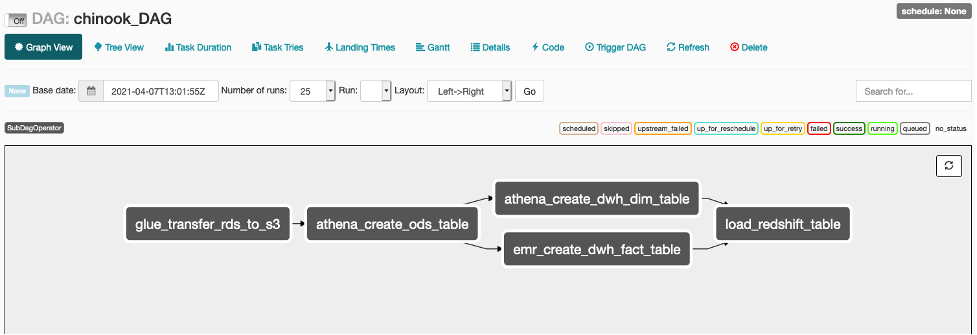
-
각 Sub DAG의 작업 또한 확인하십시오. Main DAG의 작업을 클릭하고 Zoom into Sub DAG를 클릭하면 Sub DAG의 작업을 볼 수 있습니다.
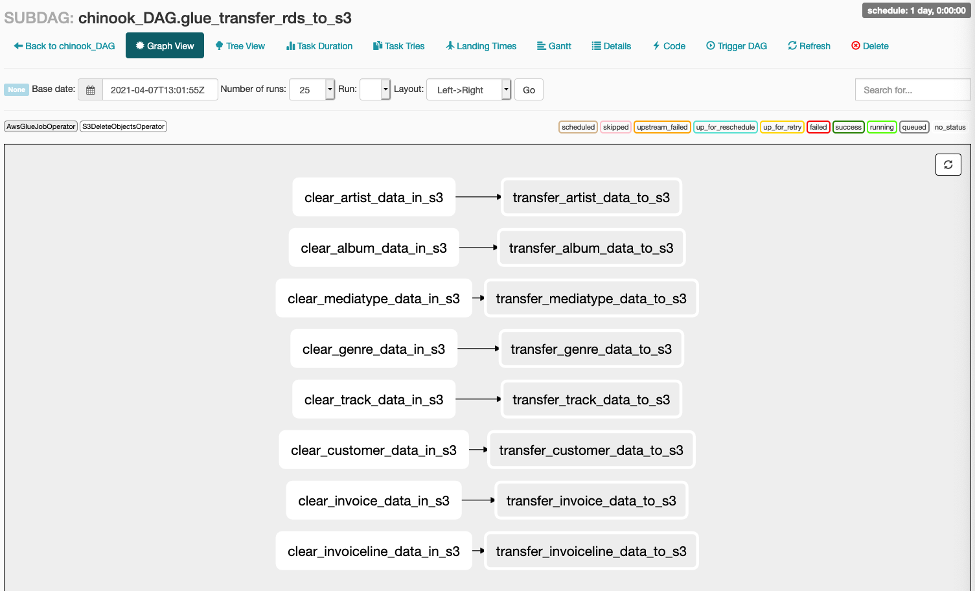
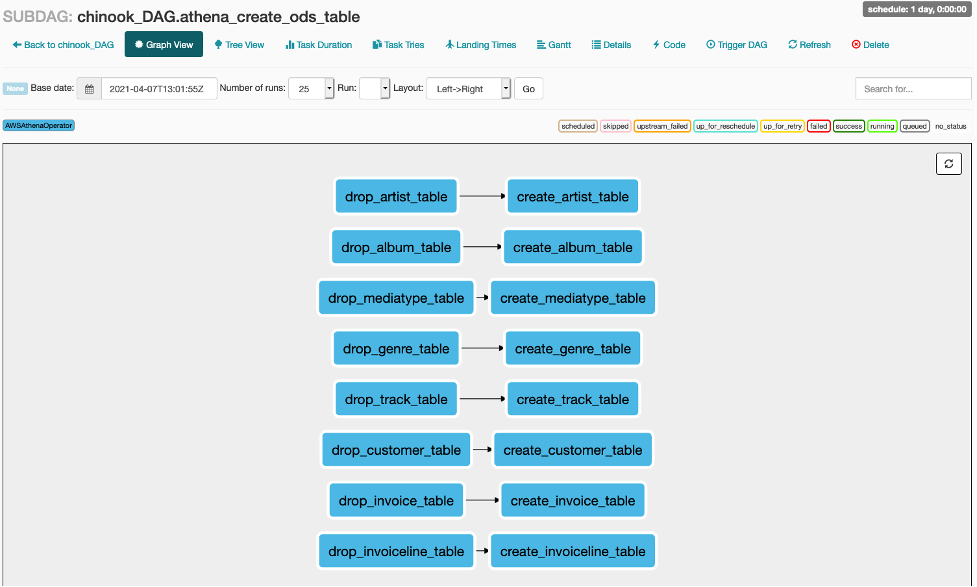
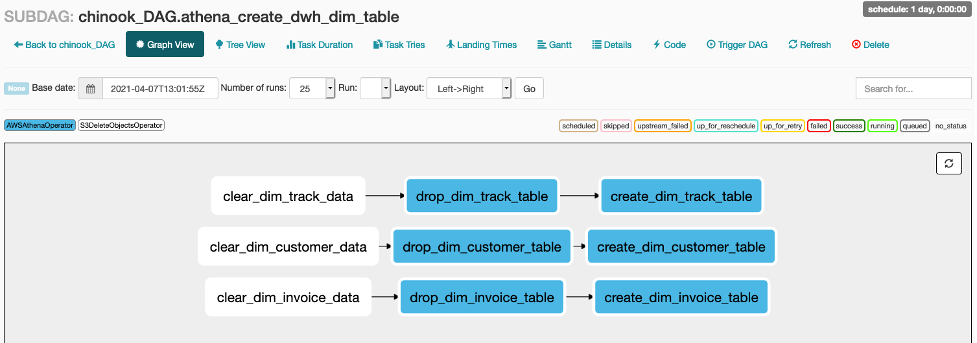
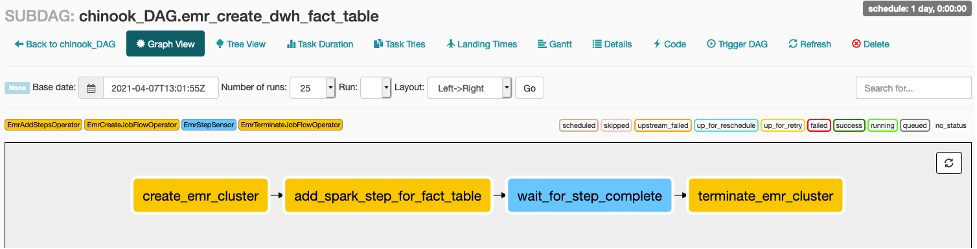
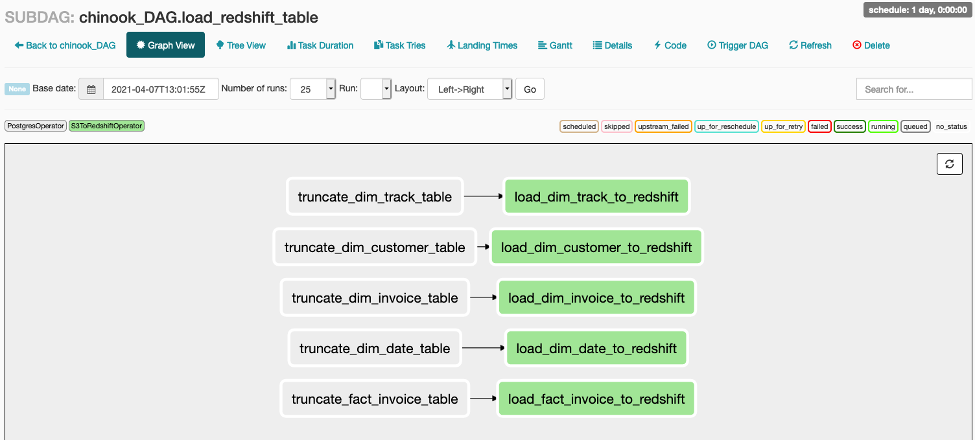
-
Toggle switch의 상태를 On으로 변경하고 DAG를 수동으로 트리거 하십시오.
첫번째 glue_transfer_rds_to_s3 작업이 트리거 되면 Glue ETL job은 Glue Studio 콘솔의 Monitoring 화면을 통해서도 실행 상태를 확인 할 수 있습니다.
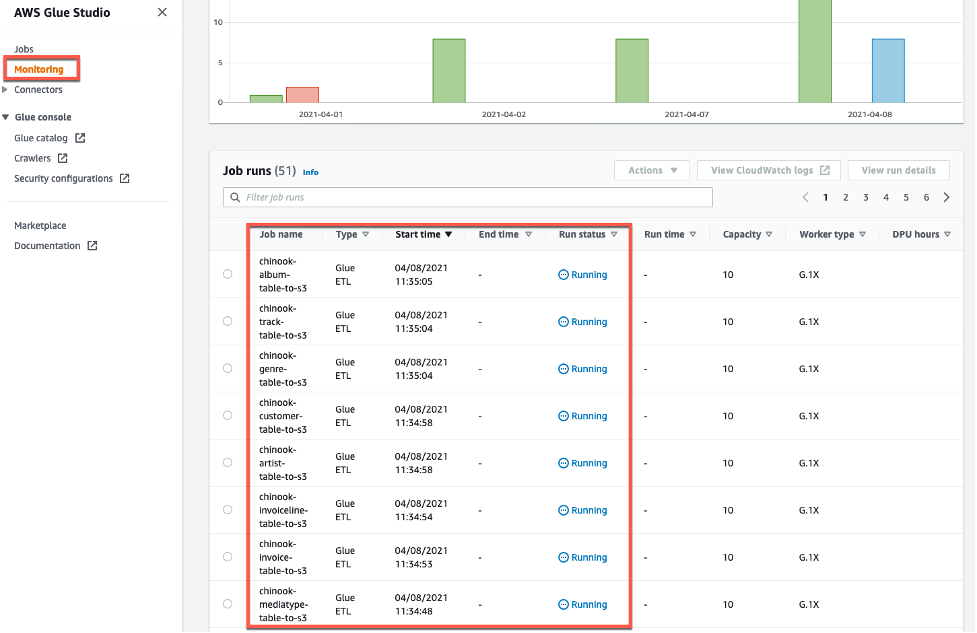
-
첫 번째 작업이 완료되면 S3 data lake bucket의 ODS 폴더 안에 RDS에서 추출 한 데이터가 각 테이블 별로 생성 됩니다. S3로 가서 각 테이블 폴더 안에 파일이 존재 하는지 확인 해 보십시오.
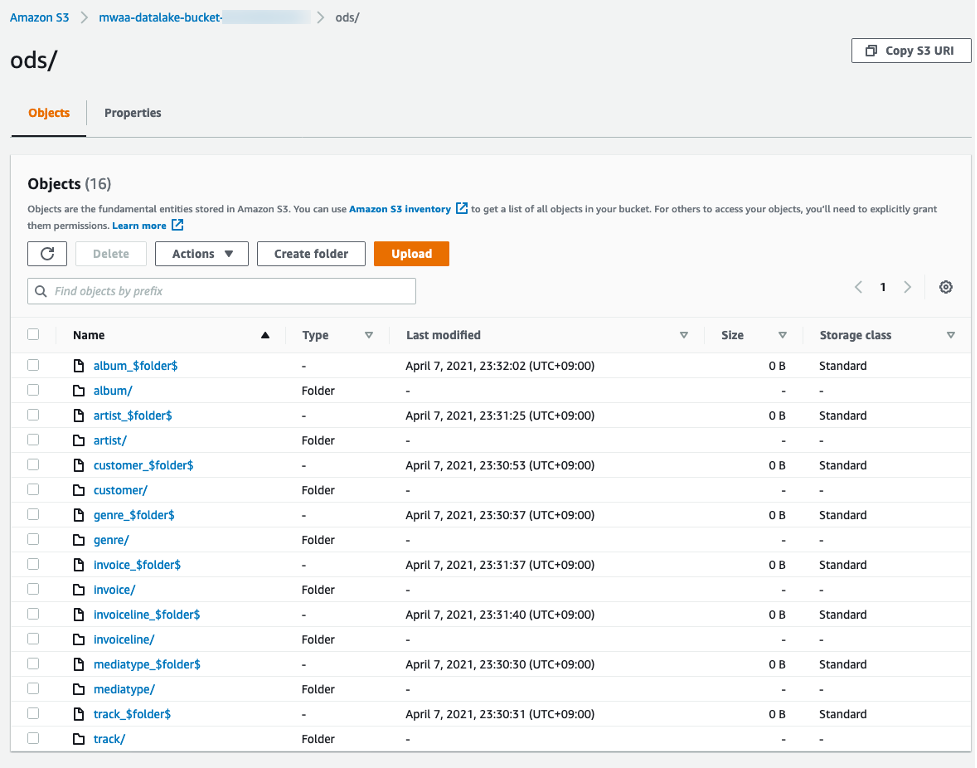
-
두 번째 athena_create_ods_table 작업이 완료되면, Glue Catalog의 chinook_ods 데이터베이스에는 다음 화면과 같은 테이블들이 생성 됩니다. Glue Catalog에 다음 테이블들이 생성 되었는 지 확인 해 보십시오.
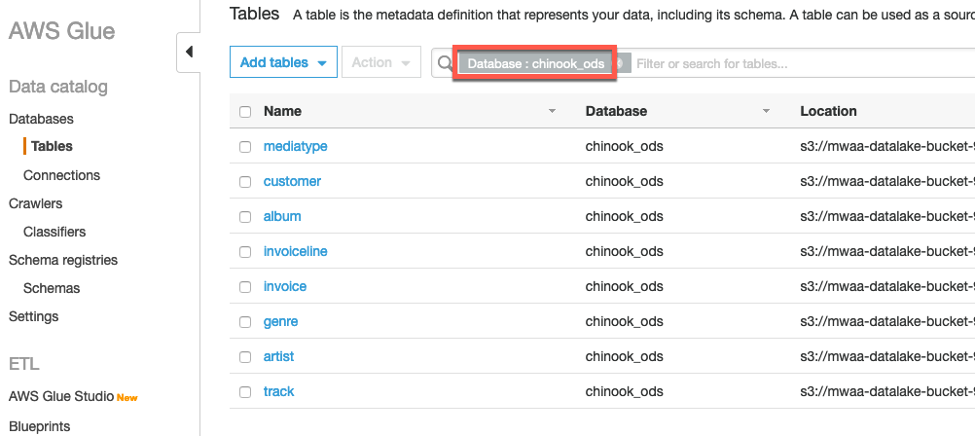
-
두 번째 작업이 완료되면 athena_create_dwh_dim_table과 emr_create_dwh_fact_table 작업은 동시에 실행됩니다. 두 작업이 완료되면 S3 data lake bucket의 dwh 폴더 안에 Star Schema 형태로 변환 된 데이터가 생성 됩니다. S3로 가서 각 테이블 폴더 안에 파일이 존재 하는지 확인 해 보십시오.
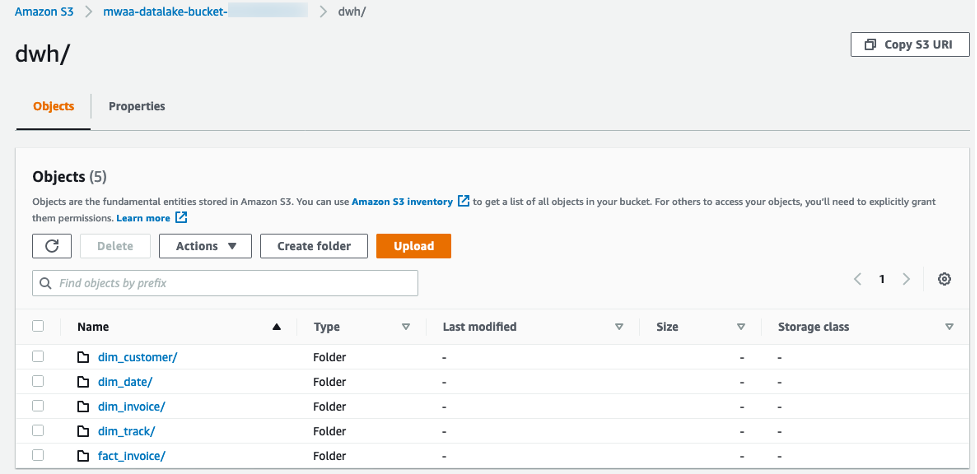
-
Glue Catalog의 chinook_dwh 데이터베이스에는 다음 화면과 같은 테이블들이 생성 됩니다. Glue Catalog에 다음 테이블들이 생성되어 있는지 확인 해 보십시오.

-
마지막 load_redshift_table 작업이 완료되면 다음 화면과 같이 Workflow의 모든 작업이 성공 상태인 것을 볼 수 있습니다.
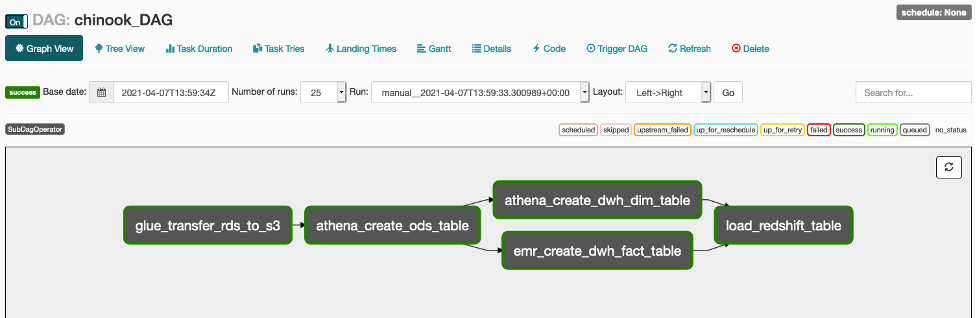
-
Redshift 테이블에 데이터가 제대로 로드 되었는 지 확인해 보겠습니다. EC2 콘솔로 가서 EC2-DB-Loader 인스턴스를 선택하고 Connect 버튼을 클릭 하여 인스턴스에 접속 하십시오.
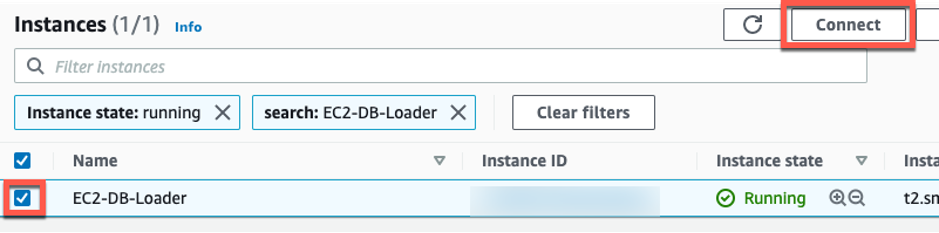
-
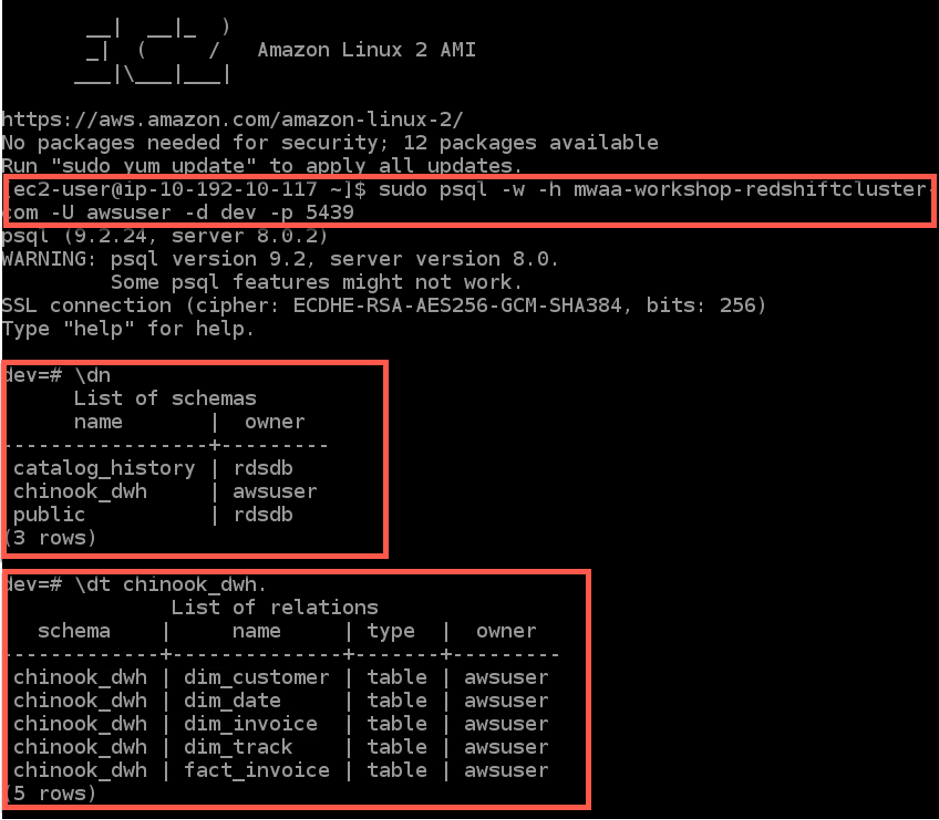
설치되어 있는 psql 클라이언트를 사용하여 Redshift cluster 연결하고 다음 Count 쿼리를 실행하여 각 테이블에 데이터가 로드 되었는 지 확인 하십시오.
psql를 실행하기 전에 <redshift_cluster_endpoint> 문구는 CloudFormation stack의 Output 탭 화면에 출력 된 RedshiftClusterEndpoint로 변경해야 합니다.
# Connect to Redshift cluster
sudo psql -w -h <redshift_cluster_endpoint> -U awsuser -d dev -p 5439
# Display schemas
\dn
# Display tables in chinook_dwh schemas
\dt chinook_dwh.
# Display count of table rows
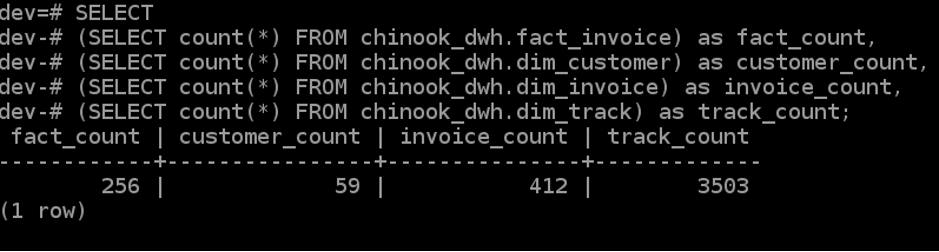
SELECT
(SELECT count(*) FROM chinook_dwh.fact_invoice) as fact_count,
(SELECT count(*) FROM chinook_dwh.dim_customer) as customer_count,
(SELECT count(*) FROM chinook_dwh.dim_invoice) as invoice_count,
(SELECT count(*) FROM chinook_dwh.dim_track) as track_count;
-
Redshift 테이블에는 2009년 1월 데이터가 로드 되었습니다. Airflow UI의 Admin->Variables 화면으로 가서 CURRENT_MONTH 변수 값을 02, 03, 04 등 순차적으로 변경하여 DAG를 재실행 해 보십시오.

-
DAG 실행이 완료 된 후 Count 쿼리를 재 실행하면 일부 테이블에 Count가 증가 한 것을 볼 수 있습니다. 즉, Airflow의 변수를 잘 활용하면 주 배치, 월 배치 등의 데이터 프로세싱 작업을 Airflow UI를 통해 쉽게 제어 할 수 있습니다.